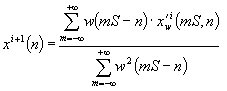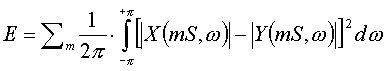|
|
|
|
Lyon's Auditory Model Inversion Technique
| The auditory system of humans consists of various parts that interact converting the sound pressure waves entering the outer ear into neural stimulus. Understanding how these parts act has been the goal of many researches during the last years thus today it is possible to describe how signals are elaborated by the auditory system, but it is also possible to analyse signals using mathematical models that reproduce the auditory features [1]. In this way we have the possibility to understand which kind of representations our higher levels in the brain use to isolate signals from noise, or to separate signals which have different pitches. If we want to reproduce the same operations, we have to be able to work on representations similar to those used by our brain. Beside that, we have also to be able to translate these representations in sound waves so that they can be objectively evaluated. To do so we have to invert the entire process we have used to get these representations, in order to obtain a sound wave. In practice all this can be done using a mathematical auditory model, by which we analyse signals and then, inverting all the stages of the model, we resynthesize the same sounds. In this work a computer based analysis-synthesis tool is described. The utility of using this system and all the possible improvements are pointed out too. As regards the auditory model, we have used Lyon's passive cochlear model [2], [3], while to achieve the model inversion we have followed, exept for some slight modifications, the work of Slaney et al. [4]. |
|
|
|
|
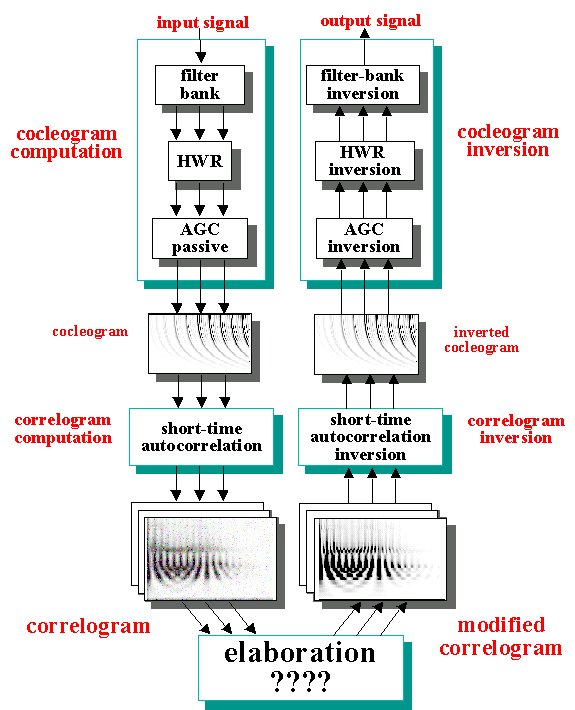
| Correlogram and Cochelagram
Inversion
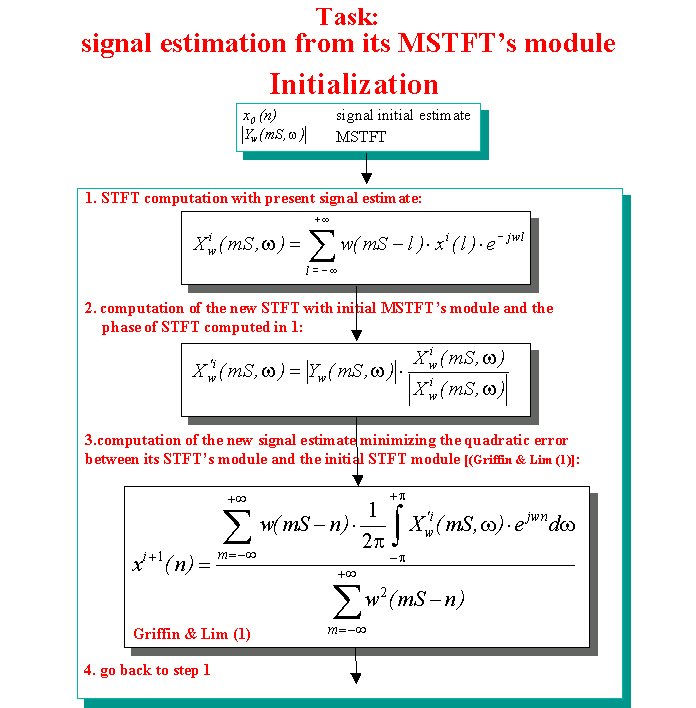
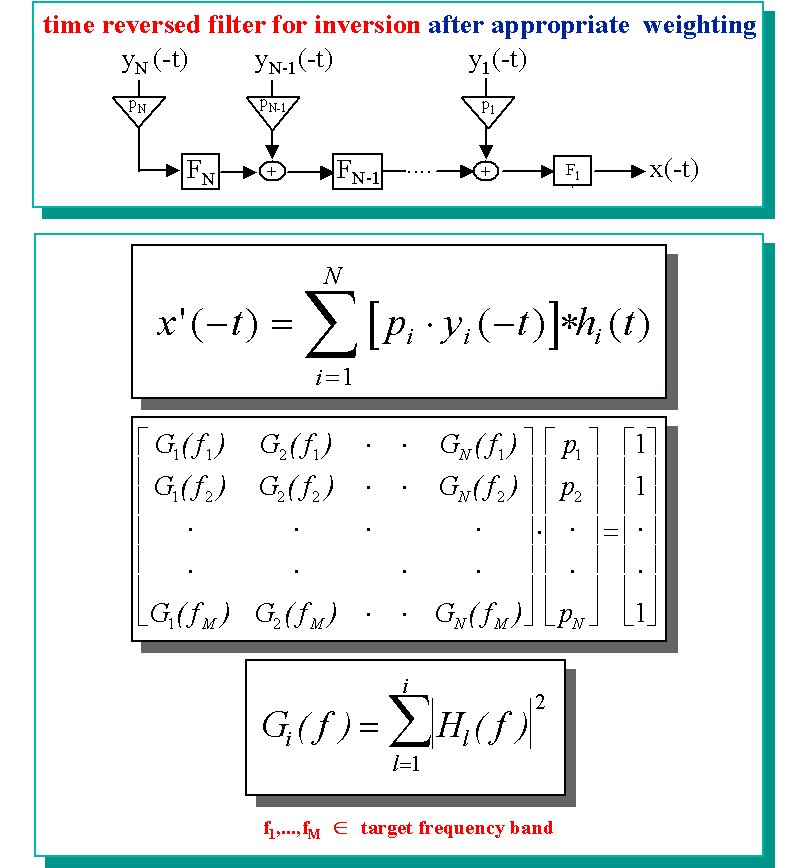
First of all it is necessary to invert the correlogram in order to get a reconstruction of the cochleagram and then from this, by another inversion, we obtain a sound wave. The correlogram is a short time autocorrelation made on all the outputs of the cochleagram. From the autocorrelation of a signal it is possible to extract the spectral power of the same signal, in fact the Fourier transform of its autocorrelation is equal to the square of its Fourier transform magnitude, that is: where is the autocorrelation of x(t). In the same way the magnitude ot the STFT can be calculated from its STA. Therefore, by simple operations, we can obtain the magnitude of the short time Fourier transforms of all the output sequences of the cochleagram. The main problem rely on the fact that we have to reconstruct signals from the magnitude of their STFTs, that is we have no information about their phases. To achieve this operation Slaney et al. suggest to use the iterative algorithm of Griffin and Lim [5]. This algorithm, at each iteration, reconstructs the phase of the signal in order to decrease the square error between the STFT magnitude of the reconstructed signal and the STFT magnitude a priori known. At each iteration the new signal is calcolated using a procedure similar to the overlap-add method. The sequences to overlap and add are obtained with the inverse Fourier Transform of the STFT composed by the known magnitude, and by the phase of the STFT of the reconstruction of the previous iteration :
where w(n) is the analysis window and S is the window shift. |
|
|
|
|
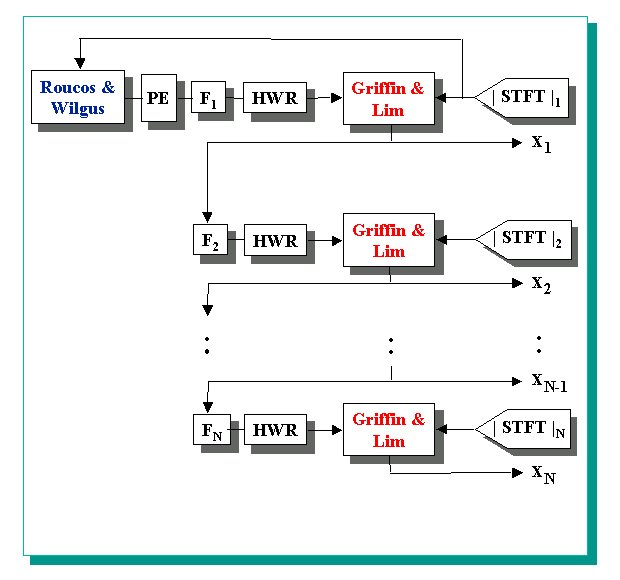
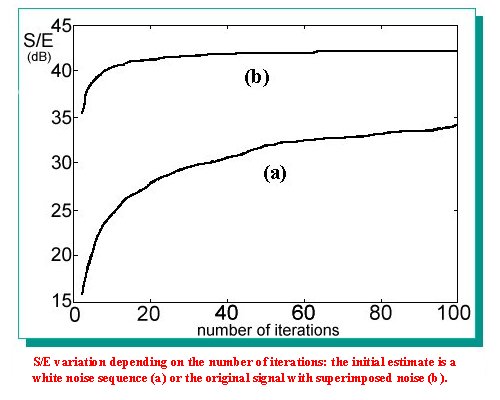
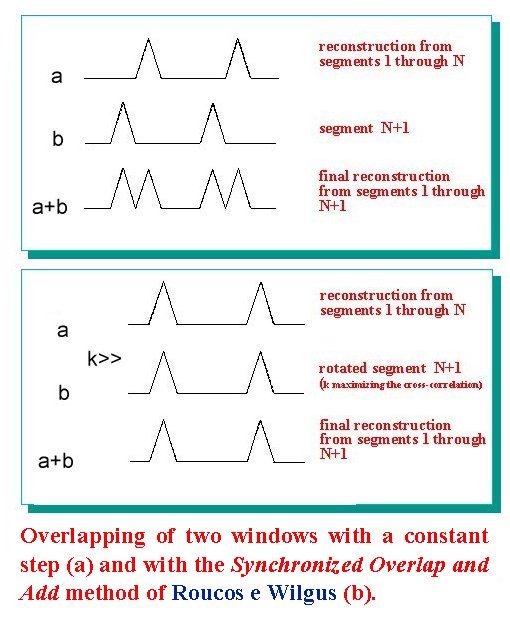
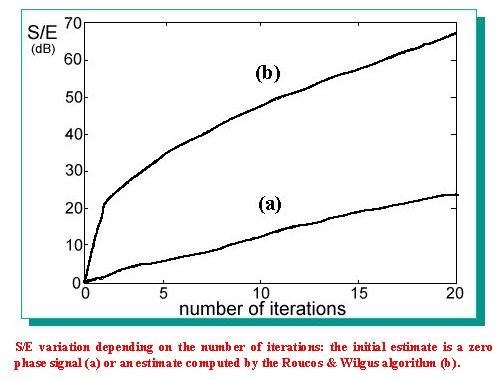
| This algorithm achieves better results if an initial non zero phase estimate of the signal is provided. In this way it is possible to reduce drastically the number of iterations. Roucos and Wilgos proposed a procedure to obtain an initial estimate to use when the algorithm of Griffin and Lim is utilised in applications of time scale modification [6]. The purpose of this procedure is to overlap and add the sequences obtained by the inverse Fourier transform of the STFT in order to maximize the crosscorrelation between the parts that are overlapped. The estimate we obtain with this method, (also called Synchronized Overlap and Add), has a phase contribution due to the fact that the sequences are shifted. In this way we obtain an estimate that can be used to reconstruct the output of the cochleagram. The procedure we have implemented works in order to maximize the normalized crosscorrelation between the parts.This solution is desirable if we don't want that too large parts of the signals overlap. We have used this method to get an estimate of the first channel of the cochleagram and to improve this estimate we have filtered it with the pre-emphasis and the first channel filters. In fact these stages give a contribution to the phase of the first channel output signal. Besides we have rectified the estimate as we know that the signals of a cochleagram have only positive values. Both the STFT magnitude of the first channel and this estimate have been used in the algorithm of Griffin and Lim to reconstruct the first channel cochlear output. To reconstruct the signals of the other channels the same algorithm has been used, however the initial estimate has been calculated in a different way. In fact, for each channel, the reconstruction of the preceding channel output has been used. Working in the time domain, to get the estimate of the i-th channel we have taken the reconstructed output of the (i-1)-st channel and we have filtered it with the i-th filter of the filter bank. In this way we have taken into account the phase contribution of this filter. The signal obtained has been subsequently half wave rectified and then used as an estimate for the algorithm of Griffin and Lim (see the figure). |
|
|
|
|
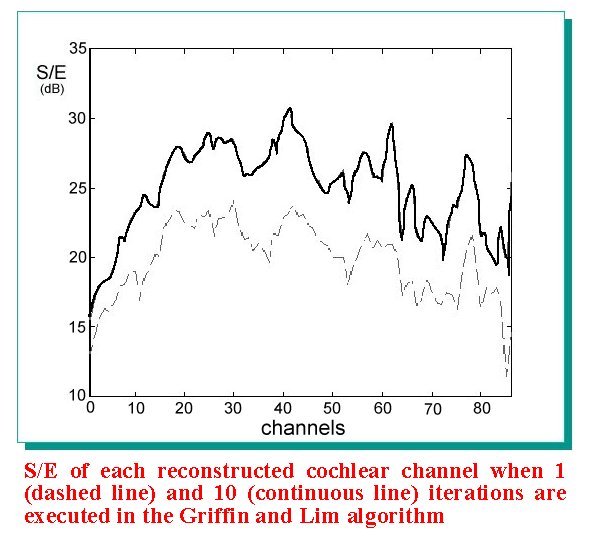
| The signal to error ratios of the reconstructions of these channels are comparable with the values obtained for the first channel reconstruction (see the figure). In the experiments made, good achievements have been obtained with about 10 iterations. For the first channel however we have preferred to execute at least 20 iterations in order to get an accurate reconstruction of this signal. Since the reconstructions of the following channels depend on the first channel quality this seems to be a reasonable choice. To have a quantitative evaluation of the error present in the reconstruction the following expression, defined in the frequency domain, can be utilized: |
|
|
|
| that is the quadratic error between the magnitude of the STFT of the signal riconstructed, ( X(mS, w) ) and the magnitude of the STFT that is a priori known ( Y(mS, w) ). | |
|
|
|
| Automatic Gain Control
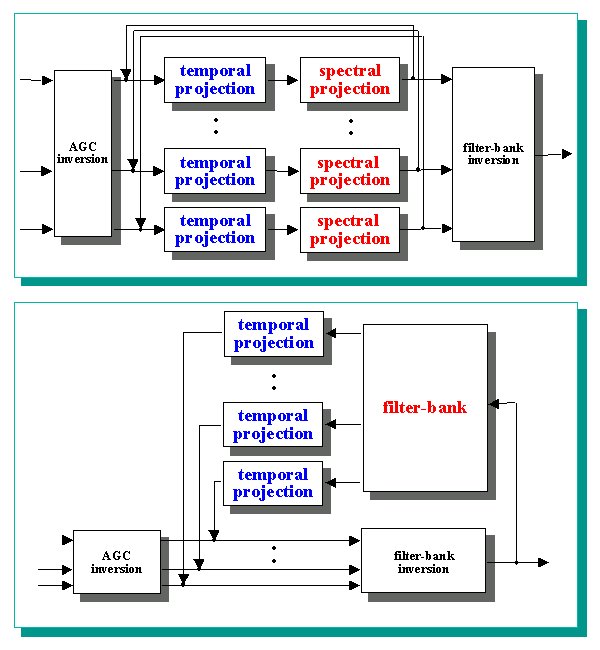
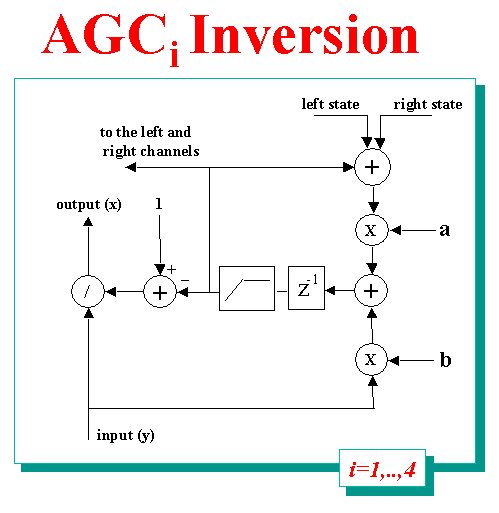
Inversion The next step is to obtain a signal coherent with the obtained inverted cochleagram. In order to do that, all the parts of the auditory model (Filter bank, HWR and AGC) have to be inverted in reversed order. The inversion of the AGC stages is relatively simple as the samples of the signal have to be divided for a value that is computable from the output values of the previous samples. |
 |
|
|
|
| Half Wave Rectification Inversion
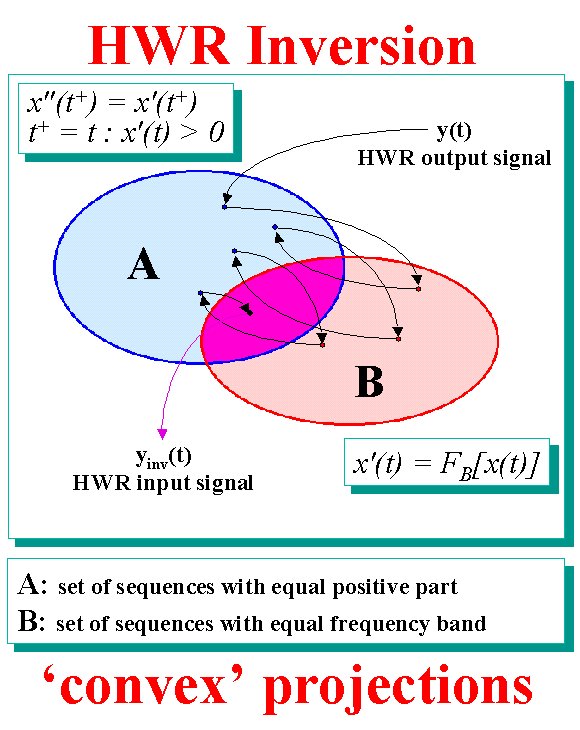
Subsequently the negative parts of the signals, that have been cut off by the HWR stages, have to be reconstructed. Slaney et al. propose the use of the convex projections tecnique [7] to invert the HWR stage. In this case two projections are made: the first in the time domain and the second in the frequency domain. The first projection is made assigning to the signal the known positive part, while the second is made filtering the signal with a bandpass filter. In our implementation the same filters of the auditory model have been used. These operations are made iteratively for each channel, and it has been empirically seen that the error stabilizes after few iterations (5-10). |
|
|
|
|
| Filter-Bank Inversion
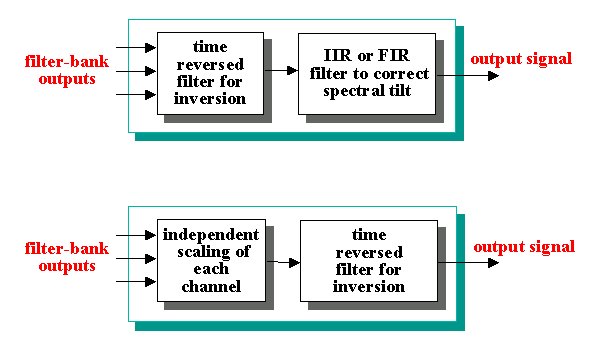
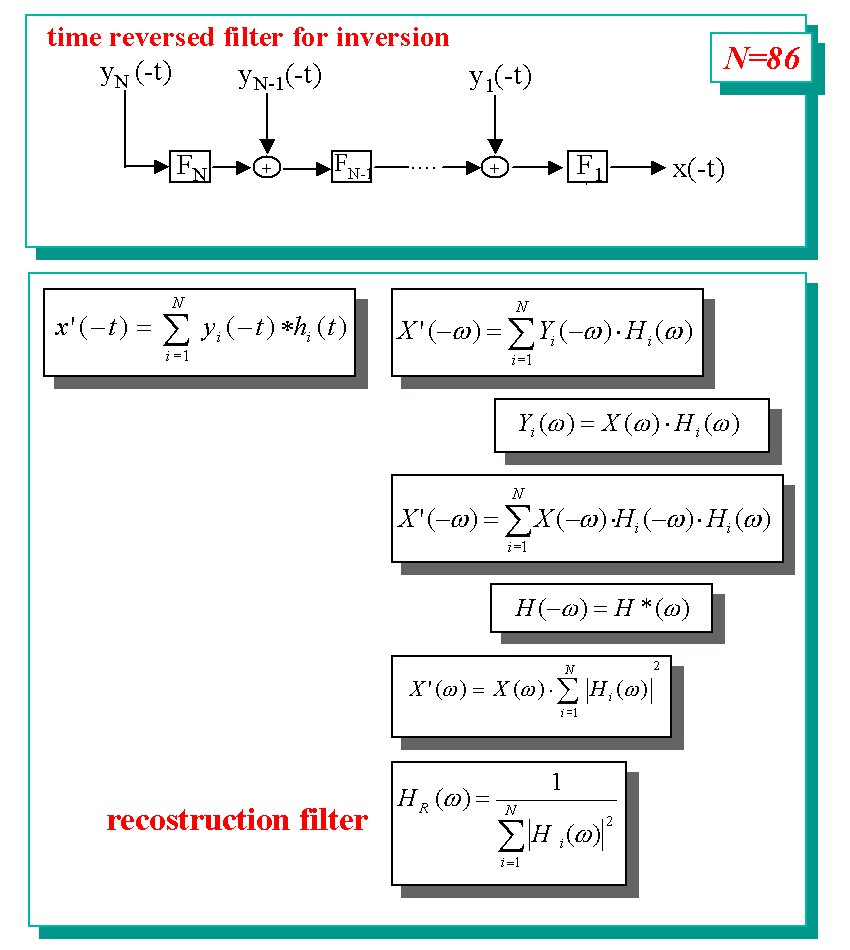
Finally the filter bank inversion have to be be executed, that is we have to reconstruct a signal from the output of the filters. This has been made with the tecnique of analysis-resynthesis using the same filter bank used for the analysis [4]. |

|
|
|
|
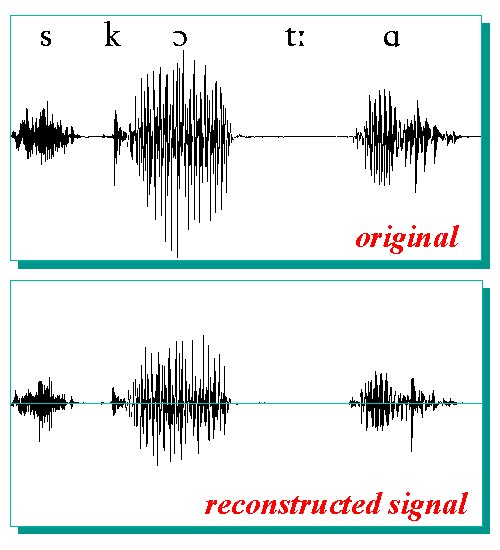
| Examples The example shown in the figure refers to the signal corresponding to the Italian word /'skOtta/ (it is hot), sampled at 16 kHz. The STAs have been calculated using the FFT executed on a number of samples that was twice the number of the analysis window length. A modified Hamming window has been used, which has the property to reduce the amount of computations in this algorithm. The window length is 256 samples while the shift between them is 64 samples. Sounds resynthesised are of good quality and the perceptual differences from the original signals are almost insignificant. |
 |
|
|
|
| Another example is given by the Bruce Springsteen song "The gost of
Tom Jod" which was inverted with this technique, and you can hear (mp3 format) the
original and the resithesized version. original (mp3)
original (wav)
|
|
|
|
|
| In the section Auditory Robust Pitch Extraction and Signal Enhanchement the possibility to synthesize sounds from a modified correlogram is investigated. In that case, the main goal is to get the information needed from a modified correlogram and then to synthesize sounds according to the modifications which have been made. The problem is that of isolating the information needed for the reconstruction of the original signal. In the case of noisy signals, the correlogram helps us to find the periodic components. Therefore it is desirable to consider only these parts and then resynthesize signals using only those. The correlogram could help us also to separate two speaker with different pitches. The problem is to group the signal of the various channels. A criterion, such as that proposed by Weintraub [8], should be used to decide wether or not a signal belongs to a particular speaker, and how to manage the uncertain signals. | |
|
|
|
References
[1] P. Cosi (1993), "Auditory modelling for speech analysis and recognition". in M. Cooke, S. Beet, M.Crawford (Eds.): Visual representation of speech signals, Wiley & Sons Chichester, 1993, pp. 205-212.
[2] R.F. Lyon (1982), "A Computational Model of Filtering, Detection, and Compression in the Cochlea." Proc IEEE-ICASSP, 1982, pp.1282-1285.
[3] M. Slaney (1988), "Lyon's Cochlear Model" (Techn. Rep. # 13) Apple Computer Inc. Cupertino, Ca., 1988.
[4] M. Slaney, D. Naar and R.F. Lyon (1994), "Auditory Model Inversion for Sound Separation", Proc. IEEE-ICASSP, Adelaide, 1994, Vol. II, pp.77-80.
[5] D.W Griffin and J.S. Lim (1984), "Signal Estimation from Modified Short-Time Fourier Transform", IEEE-ASSP, 32, 1984, pp.236-243.
[6] S. Roucos and A.M. Wilgus (1985), "High Quality Time-Scale Modification for Speech", Proc. IEEE-ICASSP, 1985, pp. 493-496.
[7] D.C. Youla and H. Webb (1982), "Image Restoration by the Method of Convex Projections: Part 1 - Theory", IEEE Trans. Medical Imaging, vol. Mi-1, 1982, pp. 81-94
[8] M. Weintraub (1984), "The GRASP Sound Separation System", Proc. IEEE-ICASSP, S. Diego, 1984, pp. 18A.6.1-18A.6.4.