|
The transmission of emotions in speech communication is a topic that has recently received considerable attention. Automatic speech recognition (ASR) and text-to-speech (TTS) synthesis are examples of popular fields in which the processing of emotions can have a substantial impact and can improve the effectiveness and naturalness of the man-machine interaction.
Speech synthesis is a by now stable technology that enables computers to talk. While existing synthesis techniques produce speech that is intelligible, few people would claim that listening to computer speech is natural or expressive. Therefore, in the last years, research in speech synthesis has been strongly focused on producing speech that sounds more natural or human-like, mainly with the aim of emulate the human behavior in man-machine communication interfaces. Meanwhile, the emotions and their role in human-to-human, human-to-machine (and vice versa) communication has become an interesting research topic. Recently, new expressive/emotive human-machine interfaces are being studied that try to simulate the human behavior while reproducing man-machine dialogues, and various attempts to incorporate the expression of emotions into synthetic speech have been made.
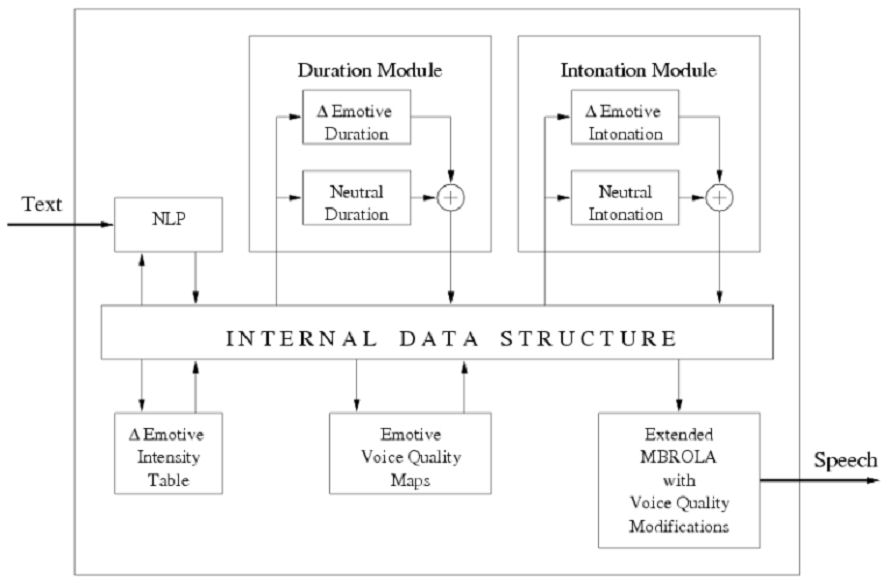
The topic of this work is an extension of our previous research on the development of a general data-driven procedure for creating a neutral “narrative-style” prosodic module for the Italian FESTIVAL Text-To-Speech (TTS) synthesizer, and it is focused on investigating and implementing new strategies for building a new emotional FESTIVAL TTS producing emotionally adequate speech starting from an APML/VSML tagged text. The new emotional prosodic modules, similarly to the neutral case, are still based on the “Classification And Regression Tree” (CART) theory. The extension to the emotional speech synthesis is obtained using a differential approach: the emotional prosodic module try to learn the differences between the neutral (without emotions) and the emotional prosodic data. Moreover, due to the fact that Voice Quality (VQ) is known to play an important role in emotive speech, a rule-based FESTIVAL-MBROLA VQ-modification module, that represents an easy way to modify the temporal and spectral characteristics of the TTS synthesized speech has also been implemented. Even if emotional synthesis still remains an attractive open issue, our preliminary evaluation results underline the effectiveness of the proposed solution. Even if emotional synthesis still remains an attractive open issue, our preliminary evaluation results underline the effectiveness of the proposed solution. |
|
The goal of this work is to investigate and implement strategies allowing a synthesizer to produce emotional speech. This goal is relevant to both Text to Speech (TTS) and Concept to Speech (CTS) synthesis, and there are many possible applications scenarios ranging from human-machine interaction in general to speaking interfaces for impaired users, electronic games, virtual agents, and story-telling scenarios.. |
CART-based
emotional prosodic modules
![]()
|
The topic of this work is an extension of our previous research on the development of a neutral TTS. A general statistical CART-based data-driven procedure for creating a “narrative-style” (neutral) prosodic module and various "emotion-style" prosodic modules were developed. This work is focused on investigating and implementing new strategies for building a new emotional FESTIVAL TTS producing emotionally adequate speech starting from an APML/VSML tagged text. The new emotional prosodic modules, similarly to the neutral case, are still based on the “Classification And Regression Tree” (CART) theory. The extension to the emotional speech synthesis is obtained using a differential approach: the emotional prosodic module try to learn the differences between the neutral (without emotions) and the emotional prosodic data (see the following Figure) click on the figure to enlarge |
|
Many of the researches in the field have
emphasized the importance of prosodic features (e.g., speech rate,
intensity contour, F0, F0 range) and the importance of the voice
quality in the rendering of different emotions in verbal communication.
In TTS technologies, voice processing algorithms for emotional speech
synthesis have been mainly focusing on the control of phoneme duration
and pitch, which are the principal parameters conveying the prosodic
information but also Voice
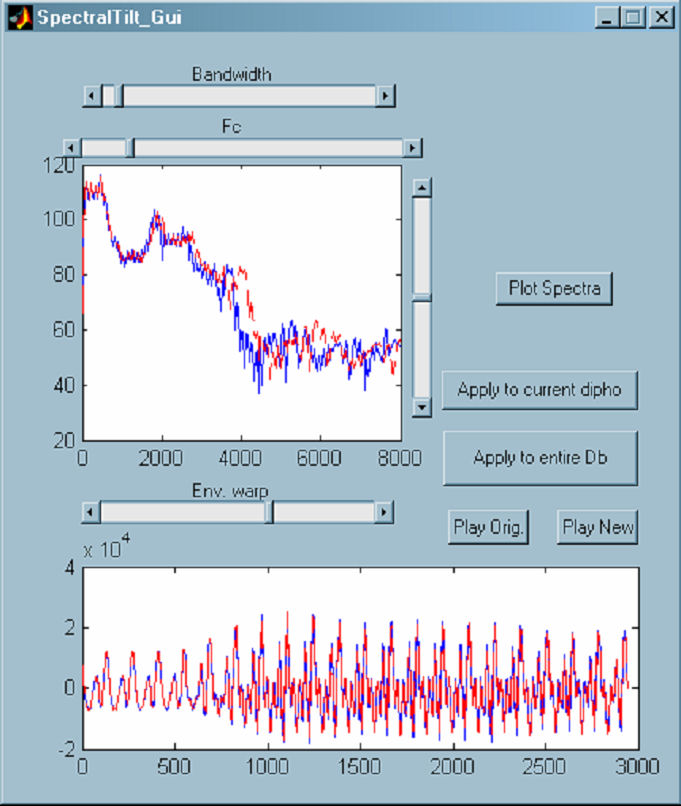
Quality (VQ) is known to play an important role in emotive speech. On the side of voice quality transformations for speech synthesis, some recent studies have addressed the exploitation of source models within the framework of articulatory synthesis to control the characteristics of voice phonation. Recently, even more sophisticated transformations have been proposed, such as transformation of spectral features for speaker conversion. Speech production in general, and emotional speech in particular, is characterized by a wide variety of phonation modalities. Voice quality, which is the term commonly used in the field, has an important role in the communication of emotions through speech, and nonmodal phonation modalities (soft, breathy, whispery, creaky, for example) are commonly found in emotional speech corpora. We discuss here a voice synthesis framework that allows to control a set of acoustic parameters which are relevant for the simulation of nonmodal voice qualities. The set of controls of the synthesizer includes standard controls for duration and pitch of the phonemes, and additional controls for intensity, spectral emphasis, fast and slow variations of the duration and amplitude of the waveform periods (for voiced frames), frequency axis warping for changing the formant position, and aspiration noise level. The following set of cues, which are among the ones that are most commonly found in investigations on emotive speech, have been selected for our analysis as voice quality correlates of emotions:
Some guidelines are given to combine these signal transformations in the aim of reproducing some nonmodal voice qualities, including soft, loud, breathy, whispery, hoarse, and tremulous voice. These voice qualities differently characterize the emotional speech. |
FESTIVAL &
MBROLA implementation issues
![]()
|
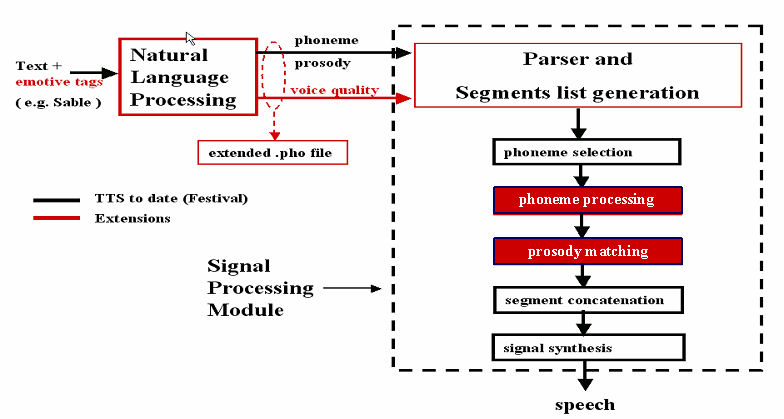
Affective/Expressive/Emotional
mark-up languages (APML/VSML)
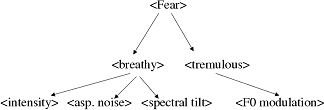
Affective tags can be included in the input text to be converted. To this aim, FESTIVAL was provided with the support for the use of affective tags through ad-hoc mark-up languages (APML/VSML), and for driving the extended MBROLA synthesis engine through the generation of voice quality controls. The control of the acoustic characteristics of the voice signal is based on signal processing routines applied to the diphones before the concatenation step. Time-domain algorithms are used for the cues related to pitch control, whereas frequency-domain algorithms, based on FFT and inverse-FFT, are used for the cues related to the short-term spectral envelope of the signal. The APML markup language for behavior specification allows to specify how to mark up the verbal part of a dialog so as to add to it the "meanings" that the graphical and the speech generation components of an animated agent need to produce the required expressions. So far, the language defines the components that may be useful to drive a face animation through the facial animation parameters (FAP) and facial display functions. A scheme for the extension of a previously developed affective presentation mark-up language (APML) has been studied. The extension of such language is intended to support voice specific controls. An extended version of the APML language has been included in the FESTIVAL speech synthesis environment, allowing the automatic generation of the extended .pho file from an APML tagged text with emotive tags. This module implements a three-level hierarchy in which the affective high-level attributes (e.g. <anger>, <joy>, <fear>, etc.) are described in terms of medium-level voice quality attributes defining the phonation type (e.g., <modal>, <soft>, <pressed>, etc.). These medium-level attributes are in turn described by a set of low-level acoustic attributes defining the perceptual correlates of the sound (e.g., <spectral tilt>, <shimmer >, <jitter>, etc.). The low-level acoustic attributes correspond to the acoustic controls that the extended Mbrola synthesizer can render through the sound processing procedure described above. In the following Figure, an example of a qualitative description of high level attributes through medium- and low- level attributes is shown.
Qualitative description of voice quality for "fear" in terms of acoustic features
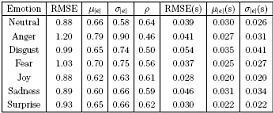
Given the hierarchical structure of the acoustic description of emotive voice, we performed preliminary experiments focused on the definition of speaker-independent rules to control voice quality within a text-to-speech synthesizer. Different sets of rules describing the high and medium level attributes in terms of low-level acoustic cues where used to generate the phonetic files to drive the extended MBROLA synthesizer. The following Table shows the low level components used to describe the given set of medium level descriptors soft, loud, whispery, tremulous, hoarse. The Table reports the control parameter and the activations level of each parameter. Values are in the range [0,1], and have different meanings for the different parameters. E.g., SpTilt=0 means maximal de-emphasis of higher frequency range, whereas SpTilt=0 means maximal emphasis; AspNoise=0 means absence of noise component, whereas AspNoise=1 means absence of voiced component, thus letting aspiration noise component alone; for F0Flut, Shimmer, and Jitter, value=0 means effect is off, whereas value=1 means effect is maximal; SpWarp=0 means maximal spectrum shrinking, and SpWarp=1 means maximal spectrum stretching. Medium level voice quality description in terms of low-level acoustic components
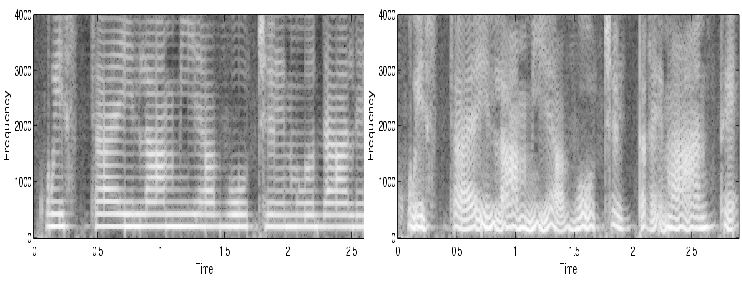
The following Figure shows the comparison of an example of synthesis obtained with tremulous voice with respect to a similar sentence obtained with modal voice. The tagged text used to generate the synthesis was as follows: <vsml> click on the figure to enlarge
Spectrograms of the utterance "Questa è la mia voce modale" ("This is my modal voice") in the left panel, and of the utterance "Questa è la mia voce tremante"("This is my tremulous voice") in the right panel. Both utterances were obtained by the modified Festival/MBROLA TTS system using a VSML input text |
|
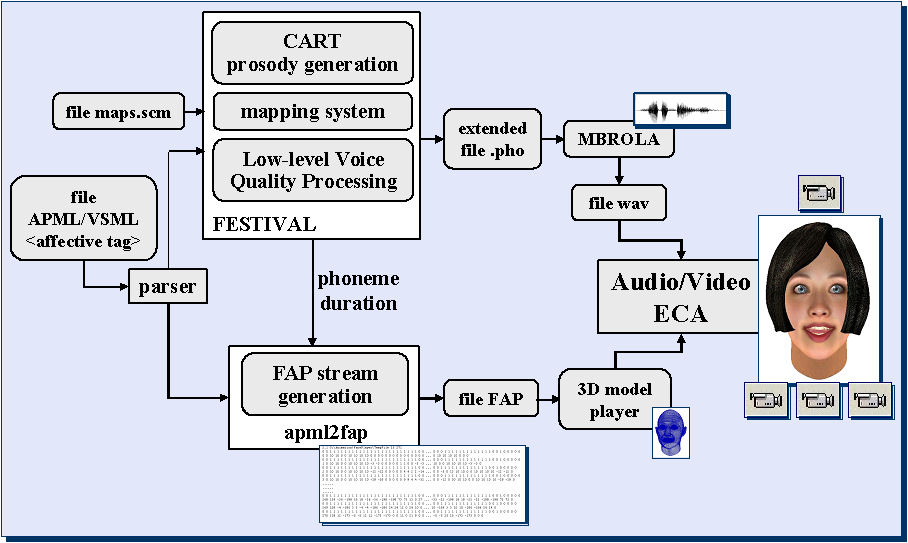
The FAP stream generation component of an MPEG-4 Talking Head such as LUCIA and the audio synthesis components have been integrated into a unique system able to produce the facial animation including emotive audio and video cues, from tagged text. The facial animation framework relies on previous studies for the realization of Italian talking heads. A schematic view of the whole system is shown in the following Figure. The modules used to produce the FAP control stream (AVENGINE), and the speech synthesis phonetic control stream (FESTIVAL), are synchronized through the phoneme duration information. The output control streams are in turn used to drive the audio and video rendering engines (i.e., the MBROLA speech synthesizer and the face model player). click on the figure to enlarge
Block diagram of the system designed to produce the facial animation with emotive audio and video cues, from tagged text |
|
In order to collect the necessary amount of emotional speech data to train the TTS prosodic models, a professional actor was asked to produce vocal expressions of emotion (often using standard verbal content) as based on emotion labels and/or typical scenarios. The Emotional-CARINI (E-Carini) database recorded for this study contains the recording of a novel (“Il Colombre” by Dino Buzzati) read and acted by a professional Italian actor, in different elicited emotions. According to the Ekman’s theory six basic emotions, plus a neutral one, have been taken into consideration: anger, disgust, fear, happiness, sadness, and surprise. The duration of the database is about 15 minutes for each emotion. |
|
Cosi, P., Fusaro, A. & Tisato, G. (2003), LUCIA a New Italian Talking-Head Based on a Modified Cohen-Massaro’s Labial Coarticulation Model, in Proceedings of Eurospeech 2003, Geneva, Switzerland, September 1-4, 127-132. d’Alessandro, C. & Doval, B. (1998), Experiments in voice quality modification of natural speech signals: the spectral approach, in Proceedings of the 3rd ESCA/COCOSDA Int. Workshop on Speech Synthesis, 277–282. De Carolis, B., Pelachaud, C., Poggi, I., Steedman, M. (2004), APML, a Markup language for believable behavior generation, in Book Life-Like Characters, Tools, Affective functions, and Applications, H. Prendinger and M. Ishizuka Eds., Springer. Drioli, C. & Avanzini, F. (2003), Non-modal voice synthesis by low-dimensional physical models, in Proc. of the 3rd International Workshop on Models and Analysis of Vocal Emissions for Biomedical Applications (MAVEBA), Florence, Italy, December 10-12. Drioli, C., Tisato, G., Cosi, P. & Tesser, F. (2003), Emotions and voice quality: experiments with sinusoidal modeling, in Proc. of Voice Quality: Functions Analysis and Synthesis (VOQUAL) Workshop, Geneva, Switzerland, August 27-29, 127-132. Gobl, C. & Chasaide, A. N. (2003), The role of the voice quality in communicating emotions, mood and attitude, Speech Communication, vol. 40, 189–212. Johnstone, T. &. Scherer, K. R (1999), The effects of emotions on voice quality, in Proceedings of the XIV Int. Congress of Phonetic Sciences, 2029–2032. Ladd, D. R., Silverman, K. E. A. , Tolkmitt, F. , Bergmann, G. , & Scherer, K. R. (1985), Evidence for the independent function of intonation contour type, voice quality, and F0 range in signaling speaker affect, Journal of the Acoustical Society of America, vol. 78, n. 2, 435–444. Magno Caldognetto, E., Cosi, P., Drioli, C., Tisato G., and Cavicchio, F. (2004), Modifications of phonetic labial targets in emotive speech: effects of the co-production of speech and emotions, Speech Communication, vol. 44, n. 1-4 , 173-185. Marchetto, E. (2004), Sistema per il controllo della voice quality nella sintesi del parlato emotivo, MThesis, Univ. of Padova, Italy. Schröder , M. & Grice, M. (2003), Expressing vocal effort in concatenative speech, in Proceedings of 15th ICPhS, Barcelona, Spain, 2589–2592. Tesser, F., Cosi, P., Drioli, C. & Tisato, G. (2004), Prosodic data driven modelling of a narrative style in FESTIVAL TTS, in Proc. of the 5th ISCA Speech Synthesis Workshop, Pittsburgh, USA, June 14-16, 185-190. |
For more information please contact :
|
Istituto di Scienze e Tecnologie della Cognizione - Sezione di
Padova "Fonetica e Dialettologia" |
![]()