![]()
Speech Synthesis
Research
Italian
TTS:
Italian synthesis with a linguistic processor

BACK | SSR Home | Research | Demos | Download ISTC-SSPD HOME
|
|
Speech Synthesis
Research |
|
|
FESTIVAL
speaks Italian!
by
|
|
|
|
|
|
| with the cooperation of | ||||

|
now |
|
||||||
![]()
|
![]()
Part of this work has been sponsored by:
|
|
MPIRO:
Multilingual Personalized Information Objects |
||
|
|
TICCA:
Technologies for Interactive Cognitive and Communicative Agents |
||
|
|
PF-STAR:
Preparing Future multiSensorial inTeraction reseARch |
|
FESTIVAL is a general multi-lingual speech synthesis system developed at the Centre for Speech Technology Research - CSTR in Edinmburgh, Scotland, UK. |
 |
|
It offers a full text to speech system with various APIs, as well an environment for development and research of speech synthesis techniques. It is written in C++ with a Scheme-based command interpreter for general control. FESTIVAL is a text-to-speech (TTS) system. Whereby unrestricted text is transformed into speech. FESTIVAL is diphone-based synthesis system utilizing the Residual-Excited LPC synthesis tecnique. In diphone synthesis, speech is created by the recombination of previously stored samples of speech, called diphones. The challenges of diphone synthesis include producing a natural sounding set of diphones, ensuring they can be joined smoothly, and manipulating the pitch and duration of the sounds. FESTIVAL is a multi-lingual system suitable for research, development and general use. It is freely available for research and educational use. CSTR has expanded its range of languages, in fact, there are TTS systems for English, Spanish and Welsh and, finally, FESTIVAL speaks Italian! |
|
|
A recording of a new Italian syntesis database with a male speaker (P.C.) has been executed at ISTC-SSPD CNR, while a similar recording with a female speaker (L.P.) has been executed at ITC-irst. The larynograph signal (electro-glottal graph - EGG) has been recorded too for a better pitch extraction. The speaker reads a set of carefully designed nonsense or true Italian words embedded in syntactically correct but semantically incorrect sentences which have been constructed to elicit particular phonetic effects. This technique ensures that the collected database only contains the required variability. Various scripts for automatic segmentation, diphone extraction and LPC analysis have been developed with the function of making faster the creation of a new voice. The database has been formatted in FESTIVAL, OGI Residual LPC and MBROLA synthesis format. |
|
Various modules have been constructed for:
|
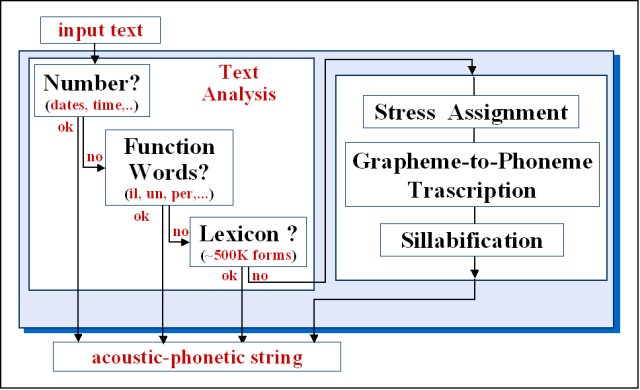
Prosodic Analysis
|
The control of prosody has a central role in TTS synthesis, in fact, one the most pressing problems in TTS is that of intonation. This divides into two areas: deciding what intonation the system should use for an utterance and the realisation of that intonation into a fundamental frequency contour. Traditionally two approaches have been used for the front end (that is, "text" or "linguistic" analysis) of speech synthesizers. The first type uses sophisticated rules to parse and tag the text. Although theoretically justified, algorithms developed to date have been so unreliable and unwieldy, that many have tried the second approach, whereby a front end is hacked together and very simple (sometimes statistical rules) are used to detect where phrasing should be placed etc. Up to now this is the week part of the Italian system, in fact, it is still "on construction". A prosodic duration module has been designed to superimpose specific duration to each diphone. A phone standard duration has been determined for each diphone from a fluent-speech database kindly provided by ITC-IRST, and these durations are modified on the basis of the phone position inside the phrase and the word. Two simple prosodic intonation modules, one for declaratory sentences and the other for question sentences, have been built making use of the stress cue and of the function-word cue previously obtained. |
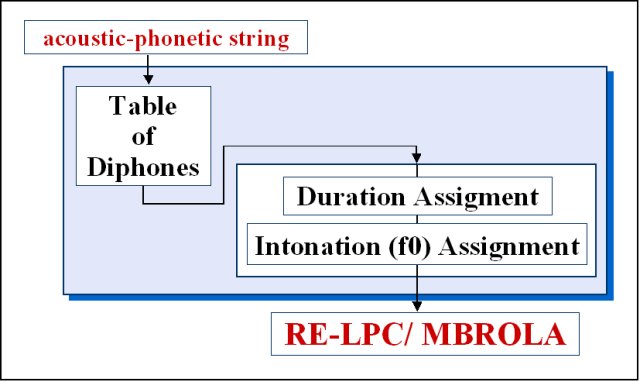
Waveform Synthesizer
|
Various waveform synthesizer have been utilized: |
|
|
|
|
FESTIVAL is diphone-based synthesis system utilizing the Residual-Exited LPC synthesis tecnique.
|
|
|
|
|
OGI RE-LPC is diphone-based synthesis system utilizing a new OGI specific Residual-Exited LPC synthesis engine.
|
|
|
|
|
MBROLA is a speech synthesizer based on the concatenation of diphones coded as PCM 16 bit linear signals. It takes a list of phonemes as input, together with prosodic information (duration of phonemes and a piecewise linear description of pitch), and produces speech samples on 16 bits (linear), at the sampling frequency of the diphone database used (it is therefore NOT a Text-To-Speech (TTS)synthesizer, since it does not accept raw text as input). This synthesizer is provided for free, for non commercial, non military applications only.
|
|
Authors
|
Piero Cosi
- Istituto di Scienze e Tecnologie della Cognizione- Sede Secondaria di
Padova "Fonetica e Dialettologia" del CNR (e-mail:
piero.cosi@pd.istc.cnr.it) with the collaboration of |
|
|
MPIRO:
Multilingual Personalized Information Objects |
||
|
|
TICCA:
Technologies for Interactive Cognitive and Communicative Agents |
||
|
|
PF-STAR:
Preparing Future multiSensorial inTeraction reseARch |
P.Cosi, R.Gretter and F.Tesser, "Festival parla italiano", in Proceedings of GFS2000, XI Giornate del Gruppo di Fonetica Sperimentale, Padova 29-30 Novembre - 1 Dicembre, 2000, (in press).
FESTIVAL: Alan W. Black (awb@cs.cmu.edu), Paul Taylor (Paul.Taylor@ed.ac.uk), Richard Caley, Rob Clark (robert@cstr.ed.ac.uk) CSTR - Centre for Speech Technology - University of Edinburgh. WWW page: http://www.cstr.ed.ac.uk/projects/festival/.
M.Macon, A.Cronk and J.Wouters and A.Kain, "OGIresLPC: Diphone synthesiser using residual-excited linear prediction", num. CSE-97-007, Department of Computer Science, Oregon Graduate Institute of Science and Technology, Portland, OR, Sep, 1997, (macon@ece.ogi.edu), pdf.
T.Dutoit, H.Leich, "MBR-PSOLA : Text-To-Speech Synthesis based on an MBE Re-Synthesis of the Segments Database", Speech Communication, Elsevier Publisher, November 1993, vol. 13, n°3-4.
T. Dutoit, An Introduction to Text-To-Speech Synthesis¸ Kluwer Academic Publishers, 1996, 326 pp.
FESTVOX: Alan W Black (awb@cs.cmu.edu), Kevin A. Lenzo (lenzo@cs.cmu.edu) Speech Group at Carnegie Mellon University. WWW page: http://www.festvox.org/.
MPIRO: Multilingual Personalized Information Objects. European Project IST-1999-10982 Version : 5. WWW page: http://www.ltg.ed.ac.uk/mpiro/
|
Piero Cosi
- Istituto di Scienze e Tecnologie della Cognizione- Sezione di
Padova "Fonetica e Dialettologia" del CNR (e-mail:
piero.cosi@pd.istc.cnr.it) |