|
|
|
|
Seneff's Joint Synchrony/Mean Rate Auditory Speech Processing
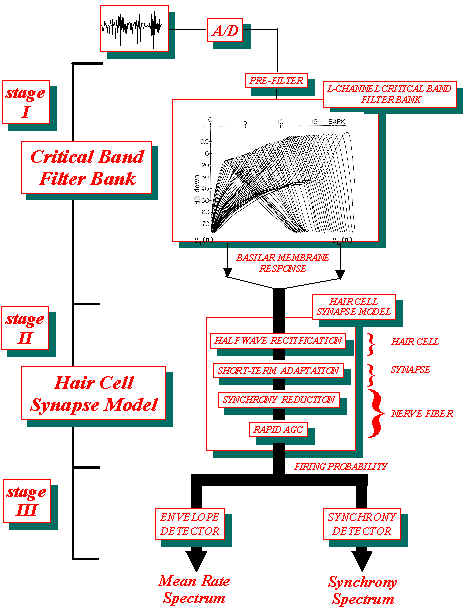
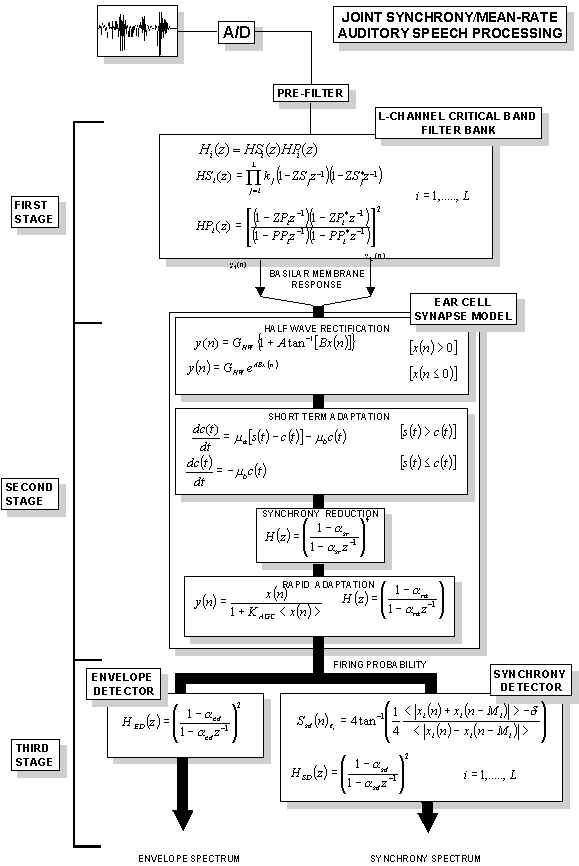
| The computational scheme proposed by S. Seneff to model the human auditory system is called Joint Synchrony/Mean-Rate model and similarly to the Lyon's model tries to capture the essential features extracted by the cochlea in response to sound pressure waves. The overall system, described in the block diagram on the left, includes three blocks. The first two of them deal with peripheral transformations occurring in the early stages of the hearing process while the third one attempts to extract information relevant to perception such as formants and to enhance sharpness of onset and offset of different speech segments. The speech signal, band-limited and sampled at 16 kHz, is first pre-filtered through a set of four complex zero pairs to eliminate the very high and very low frequency components. Then it passes through the first block, a 40-channel critical-band linear filter bank whose single channels were designed in order to fit physiological data. The second block is called the hair cell synapse model. It is nonlinear and is intended to capture prominent features of the transformation from basilar membrane vibration, represented by the outputs of the filter bank, to probabilistic response properties of auditory nerve fibers. The outputs of this stage represent the probability of firing as a function of time for a set of similar fibers acting as a group. The third and last block is a double-unit block with two parallel outputs. The Generalized Synchrony Detector (GSD), which implements the known "phase-locking" property of nerve fibers, represents the first unit and is designed with the aim of enhancing spectral peaks due to vocal tract resonances. The second unit, called Envelope Detector (ED) computes the envelope of the signals at the output of the previous stage of the model and seems more important for capturing the very rapidly changing dynamic nature of speech. The outputs of this unit should be more important in characterizing transient sounds. |
|
|
|
|
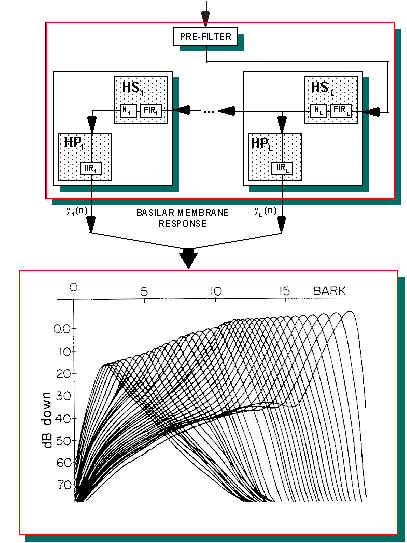
| 40-channel
critical-band linear filter bank single channels were designed in order to fit physiological data. |
|
|
|
|
Implementation formulas |
|
|
|
|
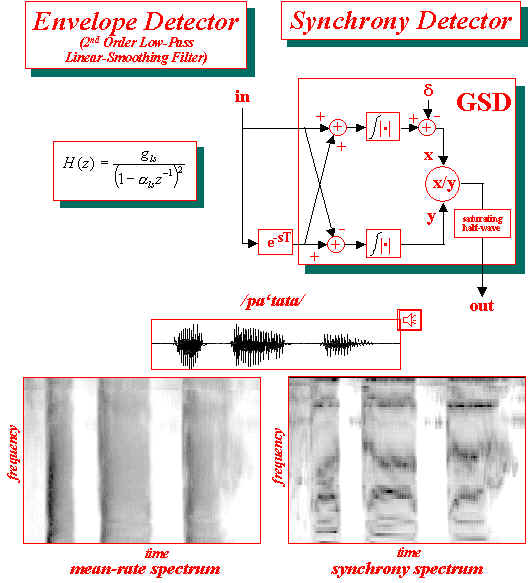
| Envelope Detector (ED) &
Generalized Synchrony Detector (GSD) Referring to the Italian word /pa'tata/ (potato), shown on the bottom of the rigth Figure, uttered in isolation by an Italian male speaker, the output of the Seneff model is quite effective in producing GSD spectra with a limited number of well defined spectral lines and also in tracking the dynamic modifications of speech. Transitions from one phonetic segment to the next are clearly delineated by onsets and offsets in the output representation better represented by the ED auditory spectrogram, and this is probably due to the forward masking mechanism which is directly included in the model. |
|
|
|
|
References for applications of Seneff Auditory Speech Processing developed at IFD
P. Cosi, Y. Bengio and R. De Mori (1990), "Phonetically-Based Multi-Layered Neural Networks for Vowel Classification", Speech Communication, North Holland, Vol. 9, No. 2, 1990, pp. 15-29. (pdf)
R. De Mori, M.J. Palakal and P. Cosi (1990), "Perceptual Models for Automatic Speech Recognition Systems", in Yovits Editor, "Advances in Computers", Academic Press, Vol. 31, 1990, pp. 99-173.
P. Cosi, L. Dellana, G. A. Mian and M. Omologo (1991), "Auditory Model Implementation on a DSP32c-Board", in Proceedings of GRETSI-91 European Conference, September 1991. (pdf)
P. Cosi (1992), "Auditory Modelling for Speech Analysis and Recognition", in Visual Representations of Speech Signals, M. Cooke, S. Beet and M. Crawford eds. John Wiley & Sons Ltd., 1992, pp. 205-212. (pdf)
P. Cosi (1993), "On The Use of Auditory Models in Speech Technology", in V. Roberto Ed., "Lecture Notes in Artificial Intelligence: Intelligent Perception Systems", Springer Verlag Publisher, Vol. 745, 1993. (pdf)
P. Cosi (1993), "SLAM: Segmentation and Labelling Automatic Module", in Proceedings of EUROSPEECH-93, 3rd European Conference on Speech Technology, Berlin, Germany, 21-23 September, 1993, Vol. 1, pp. 88-91. (pdf)
P. Cosi (1993), "SLAM: a PC-Based Multi-Level Segmentation Tool", P. Cosi, in Speech Recognition and Coding. New Advances and Trends, A.J. Rubio Ayuso and J.M. Lopez Soler edts, NATO ASI Series, Series F: Computer and Systems Sciences, N. 147, Springer-Verlag, 1995, pp. 124-127. (pdf)
P. Cosi (1997), "SLAM v1.0 for Windows: a Simple PC-Based Tool for Segmentation and Labeling", Proceedings of ICSPAT-97, International Conference on Signal Processing Applications & Technology, San Diego, CA, USA, September 14-17, 1997, pp. 1714-1718. (pdf)
P. Cosi (1998), "Auditory Modeling and Neural Networks", in A Course on Speech Processing, Recognition, and Artificial Neural Networks, Springer Verlag, Lecture Notes in Computer Science, in fase di stampa. (pdf)
|
|
Seneff's Auditory Speech Processing